Contents
1. Business Continuity Planning
Business continuity efforts are a collection of activities designed to keep a business running in the face of adversity. This adversity may come in the form of a small-scaled incident such as a single system failure or a catastrophic incident, such as an earthquake or tornado. Business continuity plans may also be activated by man-made disasters such as a terrorist attack or hacker intrusion.
Defining BCP Scope
When an organisation begins a business continuity effort, it’s easy to quickly become overwhelmed by the many possible scenarios and controls a project might consider. For this reason, the team developing a business continuity plan should take time up front to carefully define their scope
- What business activities will be covered by the plan?
- What types of systems will it cover?
- What types of controls will it consider?
The answers to these questions will help make critical prioritisation decisions down the road.
Business Impact Assessment (BIA)
This identifies and prioritises risks. The BIA is a risk assessment that follows one of the quantitative or qualitative processes that we discussed earlier in this course. The BIA begins by identifying the mission-essential functions that a business depends upon, and then traces them backwards to identify the critical systems that support those functions. Once planners have identified the affected systems, they can then identify the potential risks to those systems, and conduct a risk assessment.
This risk assessment is based upon a variety of factors:
- impact on life and safety
- impact on property and finances
- impact on the organisation’s reputation
The risk assessment should cover all of the threats that might face an organisation.
BIA Results:
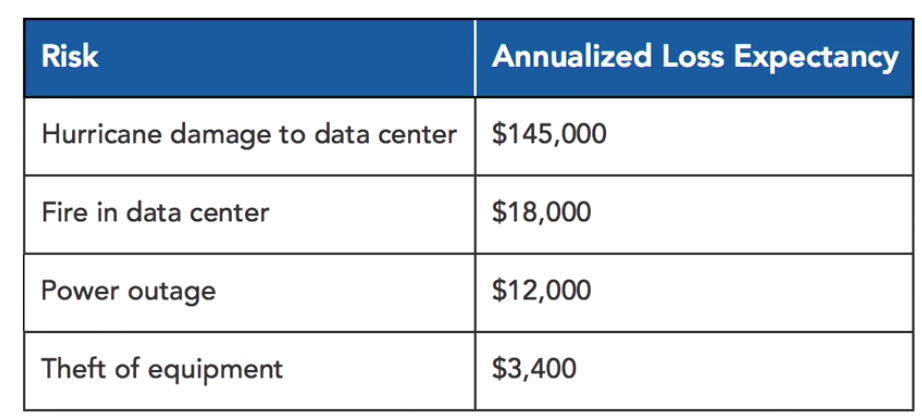
2. Business Continuity Controls
Business continuity professionals have a variety of tools at their disposal to help remediate potential availability issues
Single Point of Failure Analysis
One of the critical ways that IT professionals protect the availability of systems is ensuring that they are redundant. That simply means that systems are designed in such a way that the failure of a single component doesn’t bring the entire system down
The following example is a web server protected by a firewall and connected to the internet-
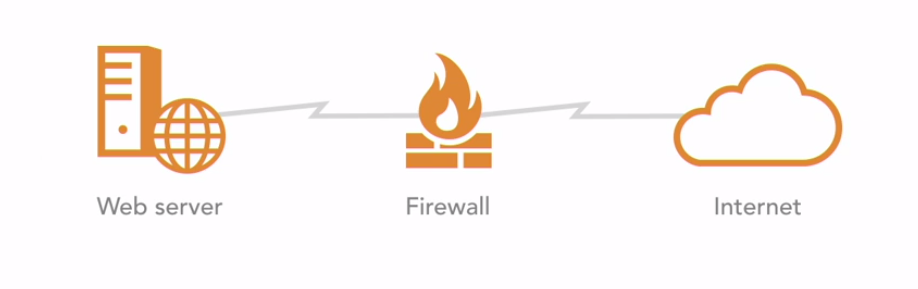
The single points of failure are:
- Single web server
- Single firewall
- 1 connection for internal and to the web
To resolve these issues we put in:
- Cluster of web servers
- High availability firewall pair
- 2 separate network connections per link

This single point of failure analysis may continue on identifying and remediating issues until either the team stops finding new issues, or the cost of addressing issues outweighs the potential benefit.
Succession Planning for Staff
One final component of business continuity planning that is often overlooked is personnel succession planning. Information technology depends upon highly skilled team members who develop, configure, and maintain systems and processes. IT leadership should work with human resources to identify those team members who are essential to continued operations, and identify potential successors for those positions, that way when someone leaves the organisation, management has already thought through potential replacements, and hopefully provided those successors with the professional development opportunities they need to step in to the departing employee’s shoes.
3. High Availability and Fault Tolerance
There are two key technical concepts that improve the availability of systems.
1. High availability (HA)
This uses multiple systems to protect against failures.
NOTE: Load balancing is a related but different concept. Load balancing uses multiple systems in an attempt to spread the burden of providing a service across those systems providing a scalable computing environment. While they use similar technologies, load balancing and high availability are different goals.
2. Fault tolerance (FT)
This helps protect a single system from failing in the first place by making it resilient in the face of technical failures. The 2 most common points of failures within a computer system are:
1. Power supplies:
they have moving parts and fail often. It is best to have redundant power supplies and connect them to different power sources where possible
2. Storage devices
The second priority of many fault tolerance efforts is protecting against the failure of a single storage device. They achieve this through the use of a technology known as RAID, redundant arrays of inexpensive disks. RAID comes in many different forms but each of them is designed to provide redundancy by having more disks than needed to meet business needs.
RAID Technologies
Mirroring(RAID1): In this approach the server contains two disks, each disk has identical data contents and when the system writes any data to one disk, it automatically makes the same change to the other disk, keeping the second disk as a synchronised copy or mirror of the primary disk.
Striping (RAID5): In this approach the system contains three or more disks and writes data across all of those disks, but also includes additional elements known as parody blocks spread across the disks. If one of the disks fails, the system can regenerate that disk’s contents by using the parody information.
RAID is a fault tolerance strategy designed to protect against a single disk failure. It is not a backup strategy, you should still perform regular data backups to protect your organisation’s information in the event of a more catastrophic failure, such as the physical destruction of an entire server.
EXAM TIP: you wont need to know detailed information about RAID but do know that mirroring requires 2 disks and striping with parity requires three
4. Disaster Recovery
Business continuity programs are designed to keep a business up and running in the face of a disaster. Sometimes continuity controls fail, or the sheer magnitude of a disaster overwhelms the organisation’s capacity to continue operations. That’s where the disaster recovery begins.
Disaster recovery is a subset of business continuity activities, designed to restore a business to normal operations as quickly as possible following a disruption.
Initial Response
- Contain the damage caused by the disaster
- Recover whatever capabilities can be immediately restored
- Possibly activating an alternate processing facility
- Possibly calling in contractors
Employees responsibilities change dramatically during disaster recovery. Flexibility is key. Organisations should plan disaster recovery responsibilities and train staff accordingly.
Disaster Recovery Communication
- Initial activation of disaster recovery team
- regular status updates for both employees in the field and leadership
- ad hoc communications capabilities to meet tactical needs
Assessment Mode
After the immediate danger to the organisation clears, the disaster recovery team shifts from immediate response mode into assessment mode. The goal of this phase is simple:
- to triage the damage to the organisation
- develop a plan to recover operations on a permanent basis
Order of Responsibility: should prioritise systems by criticality
Disaster Recovery Metrics
1. Recovery Time Objective (RTO): Maximum amount of time it should take to recover a service after a disaster
2. Recovery Point Objective (RPO): Maximum time period which data may be lost in the wake of a disaster. EG: can you lose 1 days data? 15 mins data?
EXAM TIP: Disaster recovery efforts end only when the business is operating normally in its primary facility.
5. Backups
Backups are perhaps the most important component of any disaster recovery plan. Backups provide organisations with a fail-safe way to recover their data in the event of a technology failure, human error, natural disaster, or other circumstances that result in data’s accidental or intentional deletion or modification.
Backup Media
- Tape backup: this is still a very common practice today, however, tapes are unwieldy to manage
- Disk to disk backups: write data from the primary disk to special disks set aside for backup purposes. Those backup disks may be in a separate facility, where it would be unlikely that the same physical disaster would affect both the primary and backup site
- Cloud backups: write backups directly to storage provided by cloud computing vendors, such as Amazon Web Services, Microsoft Azure, or their competitors. This provides great geographic diversity, as the backup data is stored in separately-managed facilities and cloud providers usually perform their own backups of their systems, providing an added layer of protection for customer data.
3 Primary Backup Types
- Full Backups: includes a complete copy of the data
- Differential Backups: includes all data modified since the last full backup
- Incremental Backups: includes all data modified since the last full or incremental backup. These use less space but require greater recovery time.
Snapshots
Snapshots are a special case of full backups. They leverage technology designed to capture an image of a system as it stood at a specific point in time. A snapshot may then be used at a later time to restore the system to the state it was in when the snapshot was taken. Snapshot technology is often provided by virtualisation platforms and cloud computing providers.
EXAM TIP: The exam commonly includes questions about backup types, and it’s very important that you understand not only what data is included in each backup, but also what backups would need to be restored in the event of a disaster.
Sample Question:
“Joe is the storage administrator for his company, and he performs a full backup of his systems every Sunday afternoon. He then performs differential backups every weekday evening. If the system fails on Friday morning, what backups would he need to restore?”
Answer:
1. Sundays Full backup
2. Thursdays differential backup
If it was incremental backups he would have restore
1. Sundays full backup
2. Mon, Tue, Wed and Thurs incremental backups
Media Rotation Strategies
This allows the reuse of backup media. Most restorations requests are for recent backups
Grandfather-Father-Son Rotation: in this method you have four of each media (son, father, grandfather)
- Son set of media is for weekdays
- Father set is for Fridays
- grandfather set is the last day of the month
6. Disaster Recovery Sites
During a disaster organisations may need to shift their computing functions from their primary data centre, to an alternate facility designed to carry the load when their primary site is unavailable, or non-functioning. Disaster recovery sites are alternate processing facilities, specifically designed for this purpose.
3 Types of Disaster Recovery Sites
- Hot sites:
– Fully operational data centres stocked with equipment and data
– available a moments notice
– in many cases the hot site can activate itself if the primary site fails
– Very expensive - Cold sites:
– Empty data centres stocked with the core equipment, network and environmental controls. But they don’t have the servers and data
– Activating them may take months or weeks of effort
– much cheaper option - Warm sites:
– stocked with all necessary equipment and data, but not maintained in parallel fashion
– similar in expense to hot sites
– available in hours or days
Alternate Business Processes
In addition to alternate processing facilities, organisations may incorporate alternate business processes as a component of their disaster recovery plans. For example, the organisation might move to a paper based ordering process, if an electronic order management system will remain down for an extended period of time.
7. Geographic Disaster Recovery Considerations
Offsite Backups
Backups should be stored in a facility that is sufficiently far away from the primary data centre that they will not be impacted by the same disaster. There’s no clear cut answer to the question, how far is enough? But, rather, organisations should perform location selection in a manner that is informed by their risk assessments. Generally speaking, it’s a wise practice to store backups more than 100 miles away from the primary facility, and ideally even farther away.
Redundant Data Centres
If you’re going to have two data centres operating in an active-active or active-passive configuration, it only makes sense to place them far enough apart from each other that the same disaster won’t impact both facilities. Cloud computing facilitates the use of geographically distant backups. Infrastructure as a service providers operate in many different regions and availability zones around the world, simplifying the process of shipping backups between sites and building geographic resiliency.
Legal Implications
In addition to considering the resiliency components of location selection, organisations should also take legal implications into account. When you operate a data centre in a distant jurisdiction, the data within that facility may become subject to local laws that differ from those in your primary region. For example, if you store data within the European Union, it may then fall under the provisions of the EU’s general data protection regulation
8. Testing Disaster Recovery Plans
DR Testing Goals
- Validate that the plan functions correctly
- Identify necessary plan updates
DR Test Types
- Read through: disaster recovery staff distribute copies of the current plan to all personnel involved in disaster recovery efforts, and ask those personnel to review their procedures. Team members then provide feedback about any updates needed to keep the plan current
- Walk through: involve getting everyone together around the same table to review the plan. For this reason, a walk-through is also known as a table top exercise. Walk-throughs achieve the same result as read-throughs, but are generally more effective, because they give the team the opportunity to discuss the plan together
- Simulation: the team meets together and discuss how they would respond to a specific scenario
- Parallel test: this activates the disaster recovery facility (hot or warm site) but do not switch operations to there
- Full interruption test: this switches primary operations to the alternate facility. This is the most effective test but the most disruptive
9. After Action Reports
After every activation of the disaster recovery or business continuity plans, organisations should conduct a formal review of the event and document it in an after action report. The purpose of the after action report is to create a formal record of the incident that documents the circumstances surrounding the event and identifies opportunities for future improvement.
Writing a report
An after action report should contain several major sections.
Brief executive summary: this allows a casual reader to capture the basics of the event and the major findings in a few paragraphs. When you write this summary, imagine that you are writing it for an audience who will read that section and nothing more, because that’s probably the case.
Background Information: this allows the reader to analyse the events and circumstances leading up to the incident. For example, you might include details about the state of the operating environment, external factors that contributed to the situation, and other relevant facts.
Detailed Summary: Explain what happened, being careful to cover as many of the key questions as possible. Who was involved in the event? What factors contributed to the success and/or failure of the effort? When did the event take place? Why was the disaster recovery or business continuity plan activated? Where did the incident occur, and how did the event occur?
Lessons Learned: In what ways did the organisation perform well? What areas were deficient? How could successful processes be even further improved, and how can deficiencies be corrected?
Conclusion: This should clearly outline next steps that the organisation should take based upon the lessons learned. This section should assign clear responsibility for implementing changes and timelines for completion. The next steps section should be very specific so that it may be used to hold the organisation accountable for implementing the recommended changes.
